
Summary: I look at how detailed information on industries and occupations (alongside standard demographics such as race, income, education, gender, etc.) relates to political party identifications. I find that Democratic support is higher for lawyers, social workers, those in art/media/writing industries, and members of labor unions. Republican support is higher for CEOs, financiers, engineers, and police/military. Many other categories that I looked at weren’t big deals—for example, scientists, physicians, tech workers, and accountants don’t lean heavily in either direction, and neither do people in fossil fuel, mining, manufacturing, real estate, healthcare, or various other industry categories.
I recently noticed that the U.S. General Social Survey (GSS) released an updated file in 2016 with recoded occupation and industry variables. This reminded me of something I’ve been putting off—looking more closely at how these kinds of items relate to political party preferences.
I’ve been putting it off because it’s, well, sucky. Occupation and industry variables are typically coded with hundreds of options, and you can’t just look at those groups individually because the vast majority of them don’t have enough people in the dataset to run meaningful analyses. You have to make a series of decisions to merge the individual codes into higher-level categories before analyzing them. This means going at it code-by-code—with over 250 industry codes and over 500 occupation codes—with some framework you hope makes sense, and recoding everything. Sucky.
But I bit the bullet. For the analysis in this post, I created three series of variables:
- Using industry information, I came up with very broad type-of-business categories—whether the industries relate to raw goods, manufacturing of goods, wholesale of goods, retail sale of goods, utilities, construction, real estate, providing services to businesses, providing services to consumers, hospitality, non-profit enterprises (including governments, charities, etc.), and art/media/writing (including artists, newspaper and book publishers, film and recording industries, etc.).
- Also using industry information, I did a set of variables involving various kinds of fields—chemicals, education, finance, food, fossil fuels, healthcare, machines, mining/logging, police/military, tech, textiles, transportation, and a category for professional service providers like law and accounting firms.
- I did a limited set categories using the occupation information, tagging various high-education occupations (accountants, art/media/writing folks, CEOs, educators, engineers, financiers, general managers, lawyers, scientists, social workers, tech workers, physicians, and other healthcare professionals such as nurses and pharmacists) along with a few larger mixed-education categories (medical assistants, office assistants, and police/military).
I added these industry and occupation variables to a set of the usual demographic suspects—race, religion, sexual orientation, education, income, gender, age, marriage, region, and urban/rural population density. I also included variables on membership in labor unions, working for one’s self vs. someone else, and working for government vs. private enterprise.
So the question is, how do all these things simultaneously predict political party identification? And, specifically, do any of the industry-specific and occupation-specific variables make big additions to the usual demographic picture?
Predicting party
The GSS’s party identification variable (PartyID) is a 7-point item that goes, from left to right: strong Democrat, not-strong Democrat, independent who leans Democrat, independent, independent who leans Republican, non-strong Republican, and strong Republican.
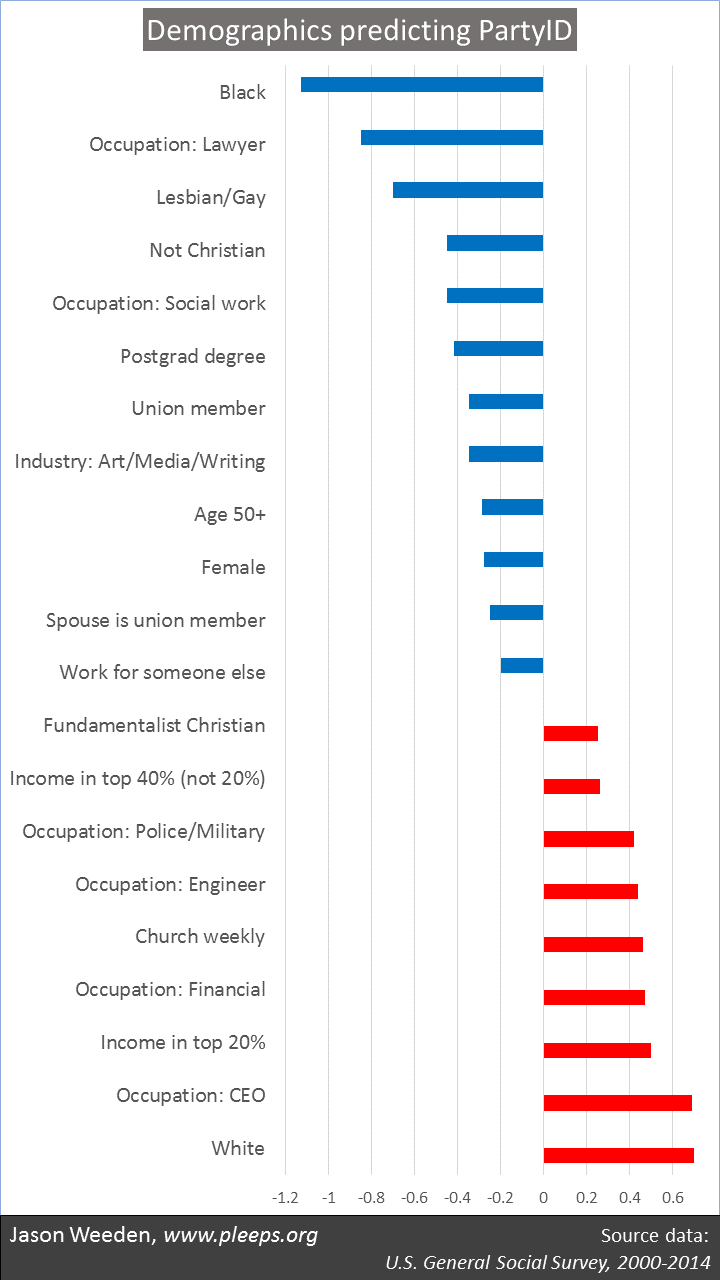
I ran an analysis having all the various demographic bits (including the usual suspects plus the job-related variables) simultaneously predict PartyID, but only allowing in the big predictors and excluding the not-so-big ones—resulting in the chart below. It’s an additive analysis, where you should be thinking it terms adding and subtracting the displayed values from a baseline condition that’s a bit to the left of center. So, think of the PartyID measure as starting with 1 for strong Democrats and ending with 7 for strong Republicans, with a middle point of 4 for independents. The baseline for the analysis is 3.68. And then all the relevant values in the chart should be added or subtracted from that baseline for the estimate of different groups’ PartyID averages. (For those of you who run stats, the analysis was a stepwise OLS regression using 1/0 categorical variables to predict PartyID, and the chart shows the raw coefficients.)
The quickest information you get from the chart below is in the contrasting values for different groups. For example, taking into account the other items in the analysis (income, education, religion, etc.), blacks are around 1.1 to the left of the baseline and whites are .7 to the right on average. Which means that blacks and whites are on average 1.8 points (i.e., 1.1 plus .7) apart from each other on the 7-point PartyID measure. (This racial gap is the biggest deal in current American politics.) But we can also see from the chart that the gap between lawyers and CEOs is pretty big as well: lawyers are about .85 to the left of the baseline and CEOs are .7 to the right, meaning that lawyers and CEOs are around 1.55 points away from each other on average (again, taking into account the other items in the analysis). This 1.55 split is bigger than the gap between gays and non-gays (.7) or even the gap between churchgoing fundamentalists and nonreligious folks (1.2). (The lawyer-vs.-CEO split calls to mind Peter Turchin’s discussions of intra-elite competition.)
 (Note: The sample size is 21,483.)
(Note: The sample size is 21,483.)
Here’s the basic story. The star demographics involve race, religion, and sexual orientation, with blacks, non-Christians (most of whom are non-religious), and lesbians/gays landing securely on the Democratic side on average, while straight white Christians (especially when evangelical and/or regularly churchgoing) anchor Republican support. There are also major subthemes involving income, education, and gender—poorer folks, the highly educated, and women skew Democratic, while richer folks and men skew Republican.
I also included some other standard demographics that didn’t end up being big enough deals to make it into the model. For instance, city-dwellers are a bit more Democratic and southerners are a bit more Republican, but not by much once you’ve got the big deals (especially race and religion) in the analysis. Also, people talk a lot about liberal youth and conservative elders, but in this sample, taking the big deals into account, older folks actually skew more Democratic (something that, it turns out, is especially driven by non-whites, where older folks are often solid Democrats while younger folks waffle more as Democratic-leaning independents).
OK, those are the demographic basics—race, religion, sexual orientation, gender, income, and education. (I find the same kinds of patterns when splitting up Pew data on party identification.) Taking all that into account, what do the job-related features add? Quite a bit, though not necessarily in all the ways one might expect. One addition is the well-known contrast between union members on the Democratic side and business-owners on the Republican side. If you sum across the relevant items in the chart, union members who work for someone else are about half a point to the left of the non-union self-employed on average. This half-point gap is comparable in size to the gap between those with family incomes in the top 20% of the GSS sample (i.e., above around $114,000 a year in 2016 dollars) vs. those in the bottom 60% (i.e., below around $76,000).
And then we get to the real focus of the analysis: the industry and occupation categories. Only a limited number were big deals—my earlier bullet-points list the many categories I created—yet the ones that stood out were interesting and mostly consistent with conventional wisdom.
Taking other demographic information into account, where do we see particular Democratic leanings? Lawyers, social workers (including counselors and psychologists), and a catch-all creative industry category that includes artists and writers as well as people who work in the news, film, recording, and related industries. And where do we see particular Republican leanings? CEOs, financiers, engineers, and police/military.
Many popular stereotypes survive: Lawyers, social workers, creative types, news media, and Hollywood on the left, and Wall Street, police, and military on the right. Keep in mind that these occupations/industries have their disproportionate leanings not simply because of basic demographics, but in addition to basic demographics. So, for instance, one might be tempted to think that creative/media types are more liberal because there are lots of educated-but-not-rich Heathens there, yet the analysis takes education, income, and religion directly into account—the left-leaning tendency of this industry cluster goes beyond ordinary demographics.
More surprising were some occupation/industry categories that weren’t big deals. As I was creating the variables, it seemed to me that folks in fossil fuel industries might be more Republican-leaning, along with, say, farmers and miners. But these kinds of splits didn’t pan out in the analysis. It also seemed to me that we might see people in education and government/non-profit fields on the left. And, actually, when I just look at college-educated whites in the GSS sample, that’s true—people in education and in government/non-profit fields (excluding police/military) do skew Democratic—but it’s not a major pattern when looking at the sample as a whole. (Having said that, keep in mind the background fact that, in general, Democrats tend to do well with people with more education than income, women, and union members, a cluster of features that often applies to educators. So there are certainly more Democrats in education fields, just not, when viewing the full sample, a ton more than you would expect given their other demographics.)
There were also plenty of industry/occupation categories that I wouldn’t have been shocked to see matter, but didn’t really. Overall, for example, there weren’t big differences when it came to accountants, scientists, tech workers, physicians, people in healthcare generally, people in real estate, construction, manufacturing, and so on.
Also keep in mind that there might be other substantial and interesting things going on with industries and occupations, but where discovering them would require category combinations that are different than those I created. Like I said at the beginning, there are lots of decisions to be made about how to categorize the basic data into usable groups, and I probably missed a range of useful splits. I’ll keep playing with these data and see if I can find others.